‘전체 평균을 한 덩어리로 보면 진실이 보이지 않는다’ → 어떤 기준으로 자르고, 어떻게 그룹을 비교할지가 분석의 출발.
Cohort (코호트) 의 기본
정의
같은 시간/조건의 시작점을 공유하는 유저 집단.
가장 흔한 코호트:
- Install Cohort: 같은 날, 주에 인스톨한 유저들 (“2024년 11월 1주차 인스톨 코호트”)
- Source Cohort: 같은 채널, 캠페인으로 들어온 유저들
- Geo Cohort: 같은 지역
- First-Purchase Cohort: 첫 결제일이 같은 유저
코호트 분석의 가장 큰 가치
- DAU 평균만 보면 어떤 코호트가 좋아지고/나빠지고 있는지 안 보임
- 최근의 평균은 모든 옛 코호트의 합이고 새 코호트의 진실은 옛날에 묻혀버림.
- 코호트별로 분리해서 봐야 변화가 보임
Cohort Heatmap
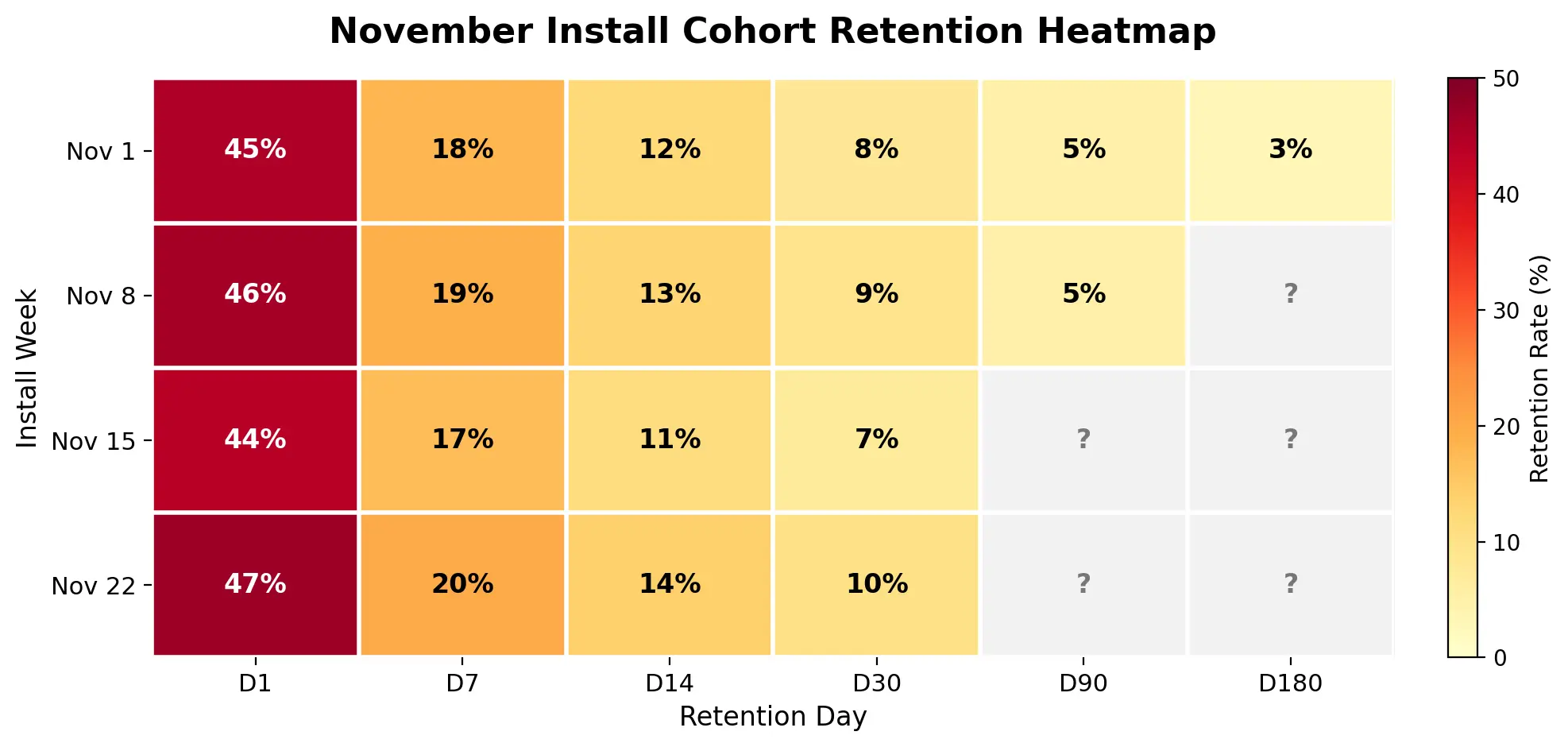
Vintage Analysis
- 빈티지(특정 시점에 발생한 코호트) 분석.
- 코호트 분석을 세로 비교하는 관점. “이번 분기 코호트가 작년 동분기 코호트보다 좋은가?” (같은 Lifecycle)
- 게임에서는 제품 개선 효과를 vintage로 봄
Source / Channel Cohort
광고 채널 / 캠페인 / 크리에이티브 단위로 묶은 코호트.
왜 중요한가
같은 인스톨이라도 어디서 왔는가에 따라 LTV가 천차만별.
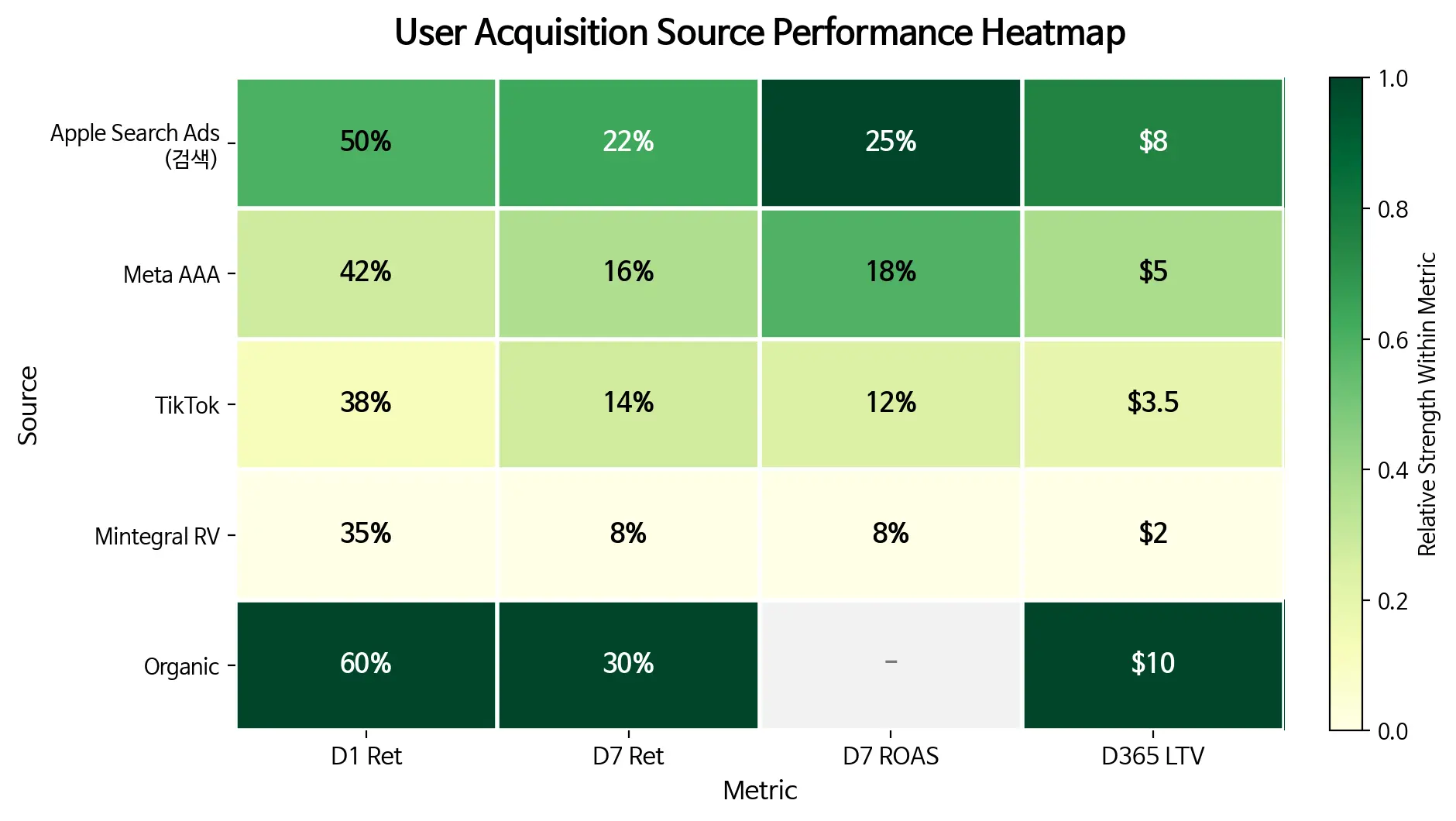
Channel Quality Index
여러 KPI를 하나의 종합 지수로.
예시: (D7 Retention × D7 ROAS × Repeat Purchase Rate) / CPI
- 식의 형태는 회사마다 다름
- 핵심은 cost-adjusted quality(한 푼당 얼마나 좋은 유저를 데려오나).
큰 채널 vs 작은 채널
크고 작은 것은 인벤토리(트래픽) 규모를 말함. 유저 질이나 가격이 아니라 광고를 노출할 수 있는 재고가 얼마나 많은가로 나누는 것.
- 큰 채널: 전 세계 수억~수십억 DAU.
- Meta (Facebook + Instagram)
- Google (UAC, YouTube)
- TikTok
- Apple Search Ads
- 작은 채널: 전체 reach는 작지만 특정 segment에 집중.
- Mintegral / Vungle / Chartboost
- Reddit Ads / Twitch Ads
- Snapchat / Pinterest
작은 채널은 삼류 채널 이런게 아니라, 작아도 자기 segment에는 매우 강함. (예 - Pinterest 여성 유저층 매우 강함)
채널 의사결정 패턴
- 작은 채널 ROAS 좋음 → 스케일링 시도 (예산 상향 조정) → ROAS 떨어짐 = 자연 한계
- 풀이 작아서 핵심 유저를 빨리 소진. 예산 늘리면 알고리즘이 덜 적합한 유저까지 긁어옴.
- 큰 채널 ROAS 보통 → 세분화 (geo / 크리에이티브 / 입찰 분리)
- 유저 풀이 잡식이라 전체 평균은 평범. 풀이 깊으니 잘 쪼개면 좋은 segment가 숨어 있음.
Behavioral Segmentation
유저의 행동 패턴에 따라 그ㅇ룹 나누기.
결제 행동
- Non-payer: 한 번도 결제 안 한 유저
- Single payer: 1회 결제
- Multi payer: 2회 이상
- Whale(고래): 누적 $100+ 또는 월 $50+
참여도
- Casual: 주 1 ~ 2회 접속
- Regular: 매일 접속
- Hardcore: 일 60분+ 또는 일 5+ 세션
진척도
- Onboarding: 튜토리얼 / 초반 콘텐츠
- Mid-game: 중반
- End-game: 거의 모든 콘텐츠 완료
광고 시청
- Ad-loyal: 매일 RV 시청
- Ad-resistant: RV 거의 안 봄
RFM 분석
Retail(소매업)에서 차용되어 게임에 적용.
- R (Recency): 마지막 활동 / 결제 시점
- F (Frequency): 결제 빈도
- M (Monetary): 누적 결제액
각 차원을 1 ~ 5로 점수화 → 5 × 5 × 5 = 125 segment. 너무 세분화되어 보통 3 ~ 5 큰 그룹으로 묶음.
Cluster 분석
K-means / DBSCAN 등으로 알고리즘적으로 segment 발견. (군집 해석)
게임에서는 해석 가능성(Interpretability) 때문에 RFM, 규칙 기반이 더 흔함.
Conversion Funnel 정밀화
행동 세그먼테이션의 한 갈래로, 인스톨에서 첫 결제까지 거치는 단계를 분해해 각 단계 전환율을 측정.
단계 분해
예시
광고 노출 → 클릭 → 스토어 도달 → 인스톨 → 첫 실행 → 튜토리얼 완료 → 첫 세션 → D1 복귀 → 첫 결제
각 단계의 전환율을 측정.
흔한 발견:
- 튜토리얼에서 50% churn → onboarding 개선
- 첫 보스전 패배 후 30% churn → 난이도 조정
- 첫 페이월 노출 후 churn ↑ → 위치, 강도 재검토
Funnel 단계 자체가 너무 많으면
- 100명이 funnel 시작 → 10단계 후 1명 남음 → 단계별 표본 부족
- 핵심 단계 5 ~ 7개로 단순화 하여 각 단계의 통계적 유의를 확보할 수 있는 수준
Lifecycle Segmentation
게임 유저의 시간에 따른 단계:
| 단계 | 정의 | 마케팅 처치 |
|---|---|---|
| New | Day 0 ~ 3 | 튜토리얼 / 첫 결제 페이월 |
| Active | 정기적 활동 | 시즌패스 / 길드 |
| At-risk | 활동 빈도 감소 중 | 리텐션 캠페인 / 푸시 |
| Dormant | 14 ~ 30일 미접속 | Re-engagement 광고 |
| Churned | 30일+ 미접속 | Reinstall 캠페인 (제한적) |
| Resurrected | 길게 휴면 후 복귀 | 재-onboarding 처치 |
Predictive Segmentation (예측 기반)
pLTV 기반
- 인스톨 후 D0 ~ D7 데이터 → D365 LTV 예측
- 분위수로 segment: top 10% pLTV / 다음 30% / 하위 60%
- top pLTV에는 VIP 처치(한정 패키지 등), 하위에는 광고 viewing 유도
Churn 예측
- 다음 7일 안에 churn할 확률 모델
- 위험 유저 → 재방문 푸시 / 보상
- 너무 일찍 보내면 인위적 churn 유도할 위험 있음. (counterintuitive)
Whale 예측
- “이 유저는 향후 30일 안에 $100+ 결제할 것” 예측
- High-touch 처치 (CS, 한정 오퍼)
Geo Segmentation
업계 통념의 Tier 시스템은 지역 티어에 따로 정리.
- CPI는 Tier 1 → 4로 갈수록 떨어지지만, LTV도 함께 떨어짐
- ROAS는 Tier 2 ~ 3에서 가장 좋게 나오는 경우 다수 (CPI 떨어지는 폭이 더 가파름)
Demographic / Psychographic
인구통계 / 심리통계 (설문 혹은 행동에서 추정)
한계
- ATT 이후 iOS에서는 demographic 자체를 측정하기 어려움
Android / Self-reported
- Google Play 세팅, Facebook 프로필 등에서 채널 측 추정
- 게임 내 자기 신고 (튜토리얼에서 성별/연령 묻기) - UX 대가가 있어 안 쓰는 경우 많음
게임 장르별 인구통계 경향
- Match-3 / Casual Puzzle: 여성 비중 60 ~ 70%, 30대+ 비중 큼
- Hyper-casual: 비교적 균등, 광범위한 연령
- 4X / SLG: 남성 비중 80%+, 30대+가 매출 대부분
- Battle Royale / Mobile MOBA: 남성 비중 높음, 10 ~ 20대
Ad-side Segmentation
광고 채널이 사용하는 segment:
- Lookalike Audience (LAL): 기존 결제 유저와 유사한 사람들. 1% / 5% / 10% LAL 등
- Custom Audience: 자체 데이터로 만든 audience (이메일 / device ID 업로드)
- Interest-based: 채널의 관심사 분류
- Re-targeting: 자사 앱, 웹 방문자 대상
ATT 이후 LAL 정확도가 떨어졌지만, AI 기반 ad retrieval / 매칭으로 부분 회복(대표적으로 Meta Andromeda)되었다고 함.
Cross-cohort 비교의 함정
Selection Bias
A 코호트와 B 코호트의 모집 방식이 다른 경우 - 단순 비교 불가능.
예: “AppLovin으로 들어온 유저 D7이 Meta로 들어온 유저 D7보다 낮음”
→ AppLovin이 나쁜 유저를 보낸 게 아니라, 다른 인구통계의 유저를 보낸 것일 수 있음. 같은 demographic 내에서만 비교해야 함.
Time Confounding
- 1월 코호트 vs 6월 코호트
- 그 사이에 게임이 바뀌었나? 시즌 효과가 다른가?
- 시간에 따른 자연 변화를 제품 변화로 오해하기 쉬움
Survivorship Bias
- 살아남은 애들만 보고 결론 내리는 편향 (전체의 특성으로 착각)
- “Day 30에 살아있는 유저의 D365 매출”을 보고 코호트 평균 LTV로 잘못 계산
- 실제로는 모든 D0 유저를 분모에 둬야 함
Simpson’s Paradox
- 전체 평균은 한 방향, 모든 부분집합 평균은 반대 방향
- 가중치 차이가 만든 착시
- 게임에서 자주 등장: 이 캠페인이 좋아 보이는데, geo로 쪼개면 모든 geo에서 나쁠 수도 있음
- 좋은 geo 쪽 비중이 높아서 전체로 보면 좋아보였던 것.
함정
- 평균만 봄: 분포가 long-tail이라 평균이 의미 없는 경우 다수
- 모든 코호트를 한 번에 합쳐 분석: vintage 차이를 놓침
- Selection bias 무시: 단순 비교에서 다른 변수가 결과를 만드는 경우
- Survivorship bias: D30 살아있는 유저의 LTV != D0 코호트의 LTV
- Simpson’s Paradox: 분해해서 보면 결론이 뒤집힘
- Segment 분할이 너무 세밀: 표본 크기 떨어져 통계적 의미 없음