들어가며
기존 관리 도구의 한계
아래는 이 프로젝트 이전에 운용하던 관리자 패널입니다. 유저 데이터 조회/수정, 로그 분석, 결제 검증, 게임 데이터 분석 등 다양한 기능을 갖춘 풀스택 관리 도구였습니다.
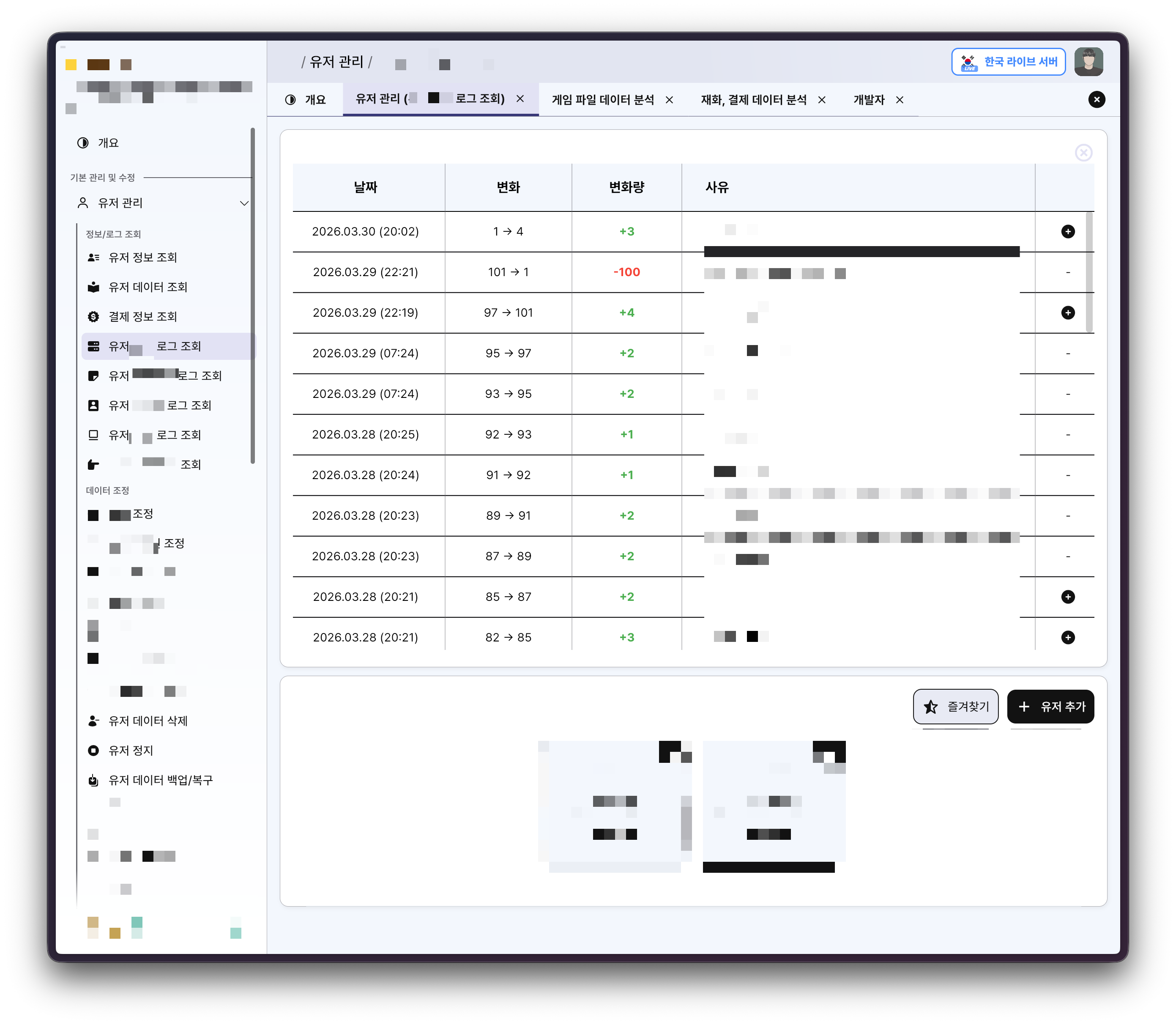
직관적이고 기능도 풍부했지만, 결정적인 문제가 하나 있었다 - 유지보수 비용이 지나치게 높았습니다. 새로운 기능을 하나 추가하려면 다음 과정을 거쳐야 했습니다.
- 게임 클라이언트에 모델 클래스를 작성합니다
- 관리자 패널의 백엔드에 API를 추가합니다
- 관리자 패널의 프론트엔드에 UI를 구현합니다
기존 기능을 수정할 때도 마찬가지로 여러 레이어를 중복 수정해야 했습니다. PR 검수 자동화, 테스트 파이프라인 등 관리 인력을 최소화하기 위해 많은 노력을 기울이고 있었지만, 관리자 도구만큼은 이 비용을 줄일 마땅한 방법이 없었습니다. 결국 게임 본체의 업데이트에 우선순위가 밀려 관리자 패널은 점점 outdated되었고, 실제 서비스 상태와 도구 사이의 괴리가 커져갔습니다.
유연성의 부재도 큰 문제였습니다. 기존 관리자 패널은 미리 구현해둔 기능만 수행할 수 있었습니다. 예를 들어 특정 버전에서 갑작스러운 결제 오류가 발생하여 주말에 긴급 문의가 몰리는 상황에서, 해당 케이스에 대한 보상 지급 기능이 패널에 없으면 개발팀에 DB 직접 쿼리를 요청하는 수밖에 없었습니다. 평시에는 필요 없는 기능을 미리 만들어둘 수도 없고, 긴급 상황에서 즉석으로 추가할 수도 없는 구조적 한계였습니다.
AI 에이전트라는 대안
그러던 중 CLI 기반 AI 에이전트가 코드베이스를 탐색하고 파일을 수정하는 모습을 보면서, “이런 에이전트를 API 수준에서 직접 구축할 수 있지 않을까?”라는 의문이 생겼습니다. 조사해보니 Gemini, GPT, Claude 등 주요 LLM API가 Function Calling을 지원하고 있었고, 이것이 이 프로젝트의 출발점이었습니다. 기능 하나를 추가할 때마다 FE/BE/모델을 모두 건드려야 하는 구조 대신, 스키마 문서 하나만 작성하면 AI가 나머지를 처리하는 구조로의 전환이었습니다.
Gemini API를 선택한 이유
기존 서비스가 GCP(Firebase, Cloud Run 등)에 강하게 결합되어 있어 Google 생태계 내에서의 통합이 자연스러웠습니다. 성능만 놓고 보면 Claude 등 다른 선택지도 있었지만, Gemini는 상위급 모델(Flash, Pro)의 가격 경쟁력이 뛰어나 사내 도구처럼 호출 빈도가 높은 서비스에 적합했습니다.
실제 구현한 프로젝트는 Gemini API의 여러 부가 기능을 사용해 벤더 종속적었지만, 빠르게 개발해야하는 입장에서 트레이드 오프라고 생각했고, Google은 신뢰할 수 있다고 생각했습니다.
물론 범용 LLM을 그대로 붙이는 것만으로는 부족합니다. GPT든 Gemini든 Claude든, 범용 모델은 사내 DB의 스키마를 모르고, 내부 규칙을 이해하지 못하며, 프로덕션 데이터를 직접 조작할 수 없습니다. 이 간극을 메우기 위해 두 가지 핵심 기술이 필요합니다.
- RAG(Retrieval-Augmented Generation)
- Function Calling 기반 Tool 시스템
이 글에서는 이 두 기술을 결합하여, 사내 폐쇄 도메인에 특화된 AI 에이전트 시스템을 설계하고 구축한 전체 과정을 다룹니다. 구현에는 TypeScript + Express.js 백엔드와 Google Gemini API를 사용했지만, 설계 패턴 자체는 LLM이나 인프라에 종속되지 않습니다.
이 글의 범위
이 글은 백엔드 AI 시스템 아키텍처에 초점을 맞추며, 프론트엔드(React) 구현 상세, 세션 JSON 스키마 명세, 배포 인프라(Docker, 클라우드 설정) 등은 다루지 않습니다. 승인 UX 등 시스템 동작에 필수적인 사용자 인터페이스 개념은 포함합니다.
시스템 아키텍처 개요
전체 시스템은 네 개의 계층으로 구성됩니다.
| 계층 | 역할 | 기술 스택 (예시) |
|---|---|---|
| API 서버 | 세션 관리, 인증, 라우팅 | Express.js + TypeScript |
| AI 오케스트레이션 | LLM 호출, Chat Loop, 프롬프트 구성 | Google Gemini API (Function Calling) |
| 도메인 지식 | 벡터 검색, 문서 임베딩, RAG 파이프라인 | Gemini Embedding + Vector DB |
| Tool 실행 | DB CRUD, 외부 API 연동, 코드 실행 | 다중 DB 커넥터, GitHub API 등 |
사용자의 자연어 요청이 처리되는 전체 흐름은 다음과 같습니다.
- 사용자가 “유저 X의 포인트를 1000 증가시켜줘”라고 입력합니다
- 백엔드가 System Prompt + Tool 선언 + 메시지 히스토리를 LLM에 전달합니다
- LLM이 먼저 RAG 검색 Tool을 호출하여 DB 스키마 문서를 검색합니다
- 검색 결과를 기반으로 적절한 DB 조작 Tool을 Function Call로 요청합니다
- 쓰기 작업이므로 사용자 승인을 대기합니다 (Human-in-the-Loop)
- 승인 후 실제 DB 수정을 실행하고, 결과를 LLM에 피드백하여 최종 응답을 생성합니다
이 흐름에서 LLM은 “생각하는 두뇌” 역할만 하고, 실제 데이터 접근과 조작은 모두 Tool 계층을 통합니다. LLM이 직접 DB에 접근하지 않으므로 보안 경계가 명확합니다.
도메인 지식 주입: RAG 파이프라인
문서 임베딩 생성
RAG 파이프라인의 첫 단계는 도메인 문서를 벡터 공간에 매핑하는 것입니다. 각 스키마 문서의 제목과 내용을 결합한 텍스트를 임베딩 모델에 통과시켜 고차원 벡터로 변환합니다.
export async function embedText(text: string): Promise<number[]> {
const result = await ai.models.embedContent({
model: "gemini-embedding-001",
contents: text,
config: {
outputDimensionality: 768,
},
});
return result.embeddings?.[0]?.values || [];
}여기서 두 가지 설계 결정이 있습니다: 임베딩 모델의 선택과 차원(dimensionality) 설정입니다.
임베딩 모델 선택: gemini-embedding-001
Google의 gemini-embedding-001은 2025년 기준 MTEB(Massive Text Embedding Benchmark) Multilingual 리더보드에서 1위를 차지한 모델입니다. 기존 text-embedding-004를 대체하며, 특히 다국어 환경에서 강점을 보입니다.
| 모델 | MTEB Score | Retrieval | Pair Classification |
|---|---|---|---|
| gemini-embedding-001 | 68.32 | 67.71 | 83.64 |
| text-embedding-004 (legacy) | lower | lower | lower |
| Voyage-3-large | competitive | competitive | - |
사내 시스템은 한국어와 영어가 혼용되는 환경이었기에, 다국어 성능이 우수한 모델을 선택하는 것이 중요했습니다.
768차원으로의 축소: Matryoshka Representation Learning
gemini-embedding-001의 기본 출력은 3072차원입니다. 그러나 본 시스템에서는 768차원으로 축소하여 사용합니다. 이것이 가능한 이유는 Google이 적용한 Matryoshka Representation Learning(MRL) 기법 덕분입니다.
MRL(Matryoshka Representation Learning) - Kusupati et al.(2022, NeurIPS)
임베딩 벡터의 앞쪽 차원에 더 중요한 정보를 집중시키는 학습 방식입니다. 마트료시카 인형처럼 전체 벡터 안에 더 작은 유효 벡터가 중첩되어 있어, 뒤쪽 차원을 잘라내도 핵심 의미가 보존됩니다.
여기서 는 미리 정의된 차원 집합(예: {768, 1536, 3072})이고, 각 차원에 대해 개별적으로 손실을 최적화합니다. 학습이 끝나면 벡터의 앞부분만으로도 충분한 표현력을 가집니다.
실제 벤치마크에서 3072차원 대비 768차원의 품질 손실은 약 0.25%에 불과합니다. 스토리지와 검색 비용은 차원 수에 비례하므로, 4배 작은 벡터로 거의 동일한 성능을 얻는 셈입니다.
| 차원 | MTEB Score | 3072 대비 품질 손실 | 스토리지 비율 |
|---|---|---|---|
| 3072 | 68.16 | - | 100% |
| 1536 | 68.17 | ~0% | 50% |
| 768 | 67.99 | ~0.25% | 25% |
거리 측정: Cosine Distance
벡터 간 유사도를 측정하는 방식으로 Cosine Distance를 채택했습니다. Cosine은 벡터의 방향만을 비교하고 크기(magnitude)를 무시하므로, 문서 길이에 따른 벡터 크기 차이에 영향받지 않습니다.
대안으로 L2(Euclidean) Distance나 Dot Product도 있습니다. L2는 절대적 위치 차이를 측정하여 크기에 민감하고, Dot Product는 정규화되지 않은 벡터에서 편향될 수 있습니다. 텍스트 임베딩처럼 의미적 방향이 중요한 경우 Cosine이 일반적으로 가장 적합합니다.
벡터 검색과 병렬 쿼리
임베딩이 준비되면, 사용자의 질의를 같은 모델로 임베딩한 후 벡터 DB에서 유사도 검색을 수행합니다.
export async function retrieveSchemaDocuments(
options: RetrieveOptions
): Promise<RetrieveResult> {
const { appName, query, limit = 5 } = options;
// 쿼리 텍스트를 임베딩으로 변환
const queryEmbedding = await embedText(query);
// 벡터 검색 실행 (Cosine Distance)
const vectorQuery = collectionRef
.where("appNames", "array-contains", appName)
.findNearest("embedding", queryEmbedding, {
limit,
distanceMeasure: "COSINE",
distanceResultField: "_distance",
});
const snapshot = await vectorQuery.get();
// ... 결과 파싱 및 반환
}여기서는 문서 DB의 네이티브 Vector Search 기능을 사용했지만, 이 패턴은 벡터 검색을 지원하는 어떤 저장소에든 동일하게 적용됩니다. Pinecone, Qdrant, Weaviate 같은 전용 벡터 DB는 물론, PostgreSQL의 pgvector 확장이나 MongoDB Atlas Vector Search도 같은 역할을 수행할 수 있습니다.
전용 벡터 DB vs 기존 DB의 벡터 확장
Pinecone, Qdrant 같은 전용 벡터 DB는 대규모(수백만 이상) 벡터에서 최적화된 인덱싱과 sub-100ms 지연시간을 제공합니다. 반면 Firestore, pgvector 같은 기존 DB의 벡터 확장은 별도 인프라 없이 기존 데이터와 함께 관리할 수 있다는 장점이 있습니다. 스키마 문서 수백~수천 건 수준의 사내 시스템에서는 후자가 운영 부담 면에서 유리합니다.
검색 효율을 높이기 위해 다중 검색어를 병렬로 처리하는 구조도 도입했습니다. 하나의 사용자 요청에서 여러 관점의 검색어를 동시에 Promise.all로 실행하고, 결과를 문서 ID 기준으로 중복 제거한 뒤 유사도가 가장 높은(distance가 가장 낮은) 항목을 우선 채택합니다. 최종적으로 상위 개 문서만 LLM 컨텍스트에 포함하여, 토큰 효율과 검색 정확도의 균형을 맞춥니다. 값은 문서 총량과 평균 길이에 따라 조정합니다.
Multi-hop Retrieval - 관련 문서 해석
단일 벡터 검색만으로는 복잡한 작업에 필요한 모든 맥락을 확보하기 어렵습니다. 예를 들어 “아이템을 추가”하려면 아이템 스키마뿐 아니라 인벤토리 구조, 아이템 타입 정의 등 연관 문서도 필요합니다.
이를 위해 각 스키마 문서에 relatedDocs 필드를 두어 문서 간 관계를 명시합니다. 검색 결과의 관련 문서를 1단계만 추가로 resolve하여, 검색 범위를 확장하면서도 무한 탐색을 방지합니다.
export async function resolveRelatedDocs(
searchResults: SchemaDoc[],
groupId: string,
): Promise<ResolvedDoc[]> {
// 이미 결과에 포함된 문서 ID 수집
const resultIds = new Set(searchResults.map((d) => d.id));
// resolve할 관련 문서 ID 수집 (중복 및 기존 결과 제외)
const idsToFetch = new Set<string>();
for (const doc of searchResults) {
for (const relId of doc.relatedDocs) {
if (!resultIds.has(relId)) idsToFetch.add(relId);
}
}
// 30개 단위 배치로 관련 문서 fetch
const ids = [...idsToFetch];
for (let i = 0; i < ids.length; i += 30) {
const chunk = ids.slice(i, i + 30);
const snapshot = await collection
.where(FieldPath.documentId(), "in", chunk)
.get();
// ... 결과 매핑
}
// 검색 결과 + 관련 문서를 결합하여 반환
}이 방식은 그래프 기반 RAG의 단순화된 형태로 볼 수 있습니다. 완전한 Knowledge Graph를 구축하는 것보다 구현과 유지보수가 간단하면서도, 단일 검색 대비 맥락 확보 능력이 크게 향상됩니다.
왜 이 전략을 선택했는가
연관 문서를 확보하는 전략은 다양합니다. AI가 검색 결과를 보고 추가 검색어를 스스로 생성하게 하거나, 문서 인덱스 목록을 제공하여 필요한 것만 골라 조회하게 하는 방식도 있습니다. 실제로 이러한 접근도 실험했지만, 문서 규모가 수백 건 이내인 환경에서는 오히려 불필요한 LLM 호출이 늘어나고 지연시간만 증가했습니다.
relatedDocs기반 1단계 resolve는 LLM 호출 없이 확정적으로 동작하므로, 소규모 문서 환경에서 가장 효율적이었습니다. 문서가 수천 건 이상으로 늘어난다면 AI 주도 검색 전략을 재검토할 필요가 있습니다.
검색어 선정 전략 - 프롬프트 엔지니어링
RAG의 성능은 임베딩 모델이나 벡터 DB보다 검색어의 품질에 더 크게 좌우되는 경우가 많습니다. 사용자의 자연어 요청을 그대로 검색어로 사용하면, 도메인 특화 문서와의 의미적 거리가 멀어질 수 있습니다.
이 문제를 해결하기 위해 System Prompt에 검색어 가이드를 명시합니다.
- 사용자가 “장신구 아이템 ‘녹슨 반지’를 추가해줘”라고 요청하면,
녹슨 반지가 아니라장신구 아이템 추가를 검색어로 사용해야 합니다. 스키마 문서는 시스템 구조를 설명하지, 개별 데이터를 나열하지 않기 때문입니다. - 도메인 용어를 가이드합니다. 예를 들어 “사용자”보다 “유저”가 문서에서 더 자주 사용되는 용어라면, 검색어에 “유저”를 쓰도록 안내합니다.
- 검색어 배열을 활용합니다.
["유저 이메일 검색", "유저 골드"]처럼 여러 관점의 검색어를 동시에 전달하여 관련 문서를 폭넓게 확보합니다.
AI 에이전트의 팔과 다리: Tool 시스템
Function Calling 개념과 학술적 배경
RAG가 AI에게 “무엇을 아는지”를 부여한다면, Tool 시스템은 “무엇을 할 수 있는지”를 부여합니다. Function Calling은 LLM이 자연어 응답 대신 구조화된 함수 호출을 반환하는 메커니즘입니다.
일반적으로 도구 학습 에이전트의 파이프라인은 네 단계로 정리됩니다.
- Task Planning - 사용자 의도를 분석하고 도구 호출 계획 수립
- Tool Selection - 적절한 도구 선택
- Tool Calling - 인자 매핑 및 도구 실행
- Response Generation - 실행 결과를 반영한 최종 응답 생성
본 시스템은 이 파이프라인을 충실히 구현하되, 3번(실행) 단계에 HITL 승인을 삽입하여 안전성을 확보합니다.
Tool Registry 패턴
Tool 시스템의 핵심은 ToolDefinition 인터페이스와 Registry 패턴입니다.
export interface ToolDefinition {
name: string;
description: string;
parameters: FunctionDeclarationSchema;
requiresApproval: boolean | ((args: Record<string, unknown>) => boolean);
execute: (context: ToolExecuteContext) => Promise<ToolResult>;
checkPermission?: (
permissions: Permissions,
args: Record<string, unknown>,
appName: string
) => PermissionResult | Promise<PermissionResult>;
}각 Tool은 이름, 설명, 파라미터 스키마, 승인 필요 여부, 실행 함수, 권한 검사 함수를 포함합니다. Registry는 이들을 Map으로 관리하며, 서버 시작 시 모든 Tool이 등록됩니다.
const tools: Map<string, ToolDefinition> = new Map();
export function register(tool: ToolDefinition): void {
tools.set(tool.name, tool);
}
export function getGeminiFunctionDeclarations(): any[] {
const declarations = [];
for (const tool of tools.values()) {
declarations.push({
name: tool.name,
description: tool.description,
parameters: tool.parameters,
});
}
return [{ functionDeclarations: declarations }];
}이 패턴의 장점은 확장성입니다. 새 Tool을 추가할 때 파일 하나를 만들고 register()만 호출하면 됩니다. LLM API에 전달되는 함수 선언은 getGeminiFunctionDeclarations()가 자동으로 생성합니다.
requiresApproval이 함수일 수 있다는 점이 핵심 설계 포인트입니다. 단순 boolean이면 해당 Tool의 모든 호출에 동일한 정책이 적용되지만, 함수로 정의하면 호출 인자에 따라 동적으로 판단할 수 있습니다. 예를 들어 DB Tool에서 get 오퍼레이션은 자동 실행하되 set이나 update는 승인을 요구하는 식입니다.
구현된 Tool 유형
본 시스템에서 구현한 Tool은 크게 네 가지 범주로 분류됩니다.
| 범주 | Tool | 역할 | 승인 정책 |
|---|---|---|---|
| DB 조작 | db-realtime | NoSQL DB CRUD + 조건부 쿼리 | 읽기: 자동, 쓰기: 승인 |
| DB 조작 | db-document | 문서 DB CRUD + 복합 쿼리 + 집계 | 읽기: 자동, 쓰기: 승인 |
| 파일 | storage | 파일 목록/읽기/업로드/삭제 | 항상 승인 |
| RAG | search-docs | 벡터 검색 기반 스키마 문서 검색 | 자동 실행 |
| VCS 연동 | vcs-repo | 저장소 파일, 커밋, 릴리즈 조회 | 자동 실행 |
| VCS 연동 | vcs-issues | 이슈 CRUD, 댓글 관리 | 읽기: 자동, 쓰기: 승인 |
| 에셋 | asset-manage | 세션 파일 업로드/읽기/검색/분석 | 조건부 |
| 위임 | subagent | LLM 내장 도구 위임 (코드 실행, 웹 검색) | 조건부 |
Tool 이름의 범용화
위 표의 Tool 이름은 설계 패턴을 설명하기 위해 범용화한 것입니다. 실제 구현에서는 대상 DB나 외부 서비스에 맞는 이름을 사용합니다.
Subagent - LLM 내장 도구 위임
일부 작업은 AI 에이전트가 직접 처리하기보다 별도의 LLM 세션에 위임하는 것이 효율적입니다. 본 시스템의 Subagent Tool은 두 가지 내장 도구를 위임합니다.
- Code Execution: Python 샌드박스에서 데이터 가공, 통계 계산, 포맷 변환 등을 수행합니다. 메인 에이전트가 코드를 직접 작성하지 않고, 목적과 컨텍스트만 전달하면 서브에이전트가 코드를 생성하고 실행합니다.
- Web Search: 외부 정보가 필요할 때 웹 검색을 수행합니다. 사내 문서에 없는 최신 API 변경사항이나 라이브러리 문서를 조회할 때 유용합니다.
Subagent 패턴이 필요한 이유
본 시스템 구축 시점의 Gemini API에서는 커스텀 Function Calling과 Built-in Tool(code_execution, google_search)을 동시에 사용할 수 없었습니다. 따라서 메인 에이전트는 커스텀 Tool만 사용하고, 내장 도구가 필요하면 별도 세션의 서브에이전트에 위임하는 구조를 택했습니다. 최근 Gemini 3 모델부터는 이 제약이 해제되어 단일 에이전트로의 통합도 가능해졌습니다.
안전한 실행: Human-in-the-Loop 승인 시스템
왜 HITL인가
AI 에이전트가 프로덕션 데이터베이스를 직접 수정하는 시스템에서, 안전장치 없는 자동 실행은 치명적일 수 있습니다. LLM은 확률적 모델이므로 항상 정확한 결과를 보장하지 않으며, 한 번의 잘못된 쓰기 작업이 실 서비스에 즉각적인 영향을 미칠 수 있습니다.
Human-in-the-Loop(HITL)는 자동화된 AI 시스템에 인간의 판단을 삽입하는 설계 패턴입니다.
본 시스템은 읽기는 자동, 쓰기는 승인이라는 원칙을 따릅니다. 데이터 조회는 부작용이 없으므로 즉시 실행하고, 데이터 수정/삭제/생성 같은 부작용이 있는 작업은 반드시 사용자의 명시적 승인을 거칩니다.
승인 판단 로직
승인 필요 여부는 Tool별로 정의되며, 정적 boolean 또는 인자를 받는 함수로 설정됩니다.
export function toolRequiresApproval(
toolName: string,
args: Record<string, unknown>
): boolean {
const tool = getTool(toolName);
if (!tool) return false;
if (typeof tool.requiresApproval === "function") {
return tool.requiresApproval(args);
}
return tool.requiresApproval;
}DB Tool의 경우 오퍼레이션 유형에 따라 동적으로 판단합니다.
get,query오퍼레이션: 자동 실행 (부작용 없음)set,update,delete오퍼레이션: 승인 필요- 루트 경로 또는 최상위 레벨 쓰기: 항상 차단 (안전장치)
승인이 필요한 Tool이 호출되면 세션 상태가 awaiting_approval로 전환되고, Chat Loop가 일시 중단됩니다. 사용자에게는 AI가 수행하려는 작업의 상세 내용 - Tool 이름, 파라미터, AI의 설명 텍스트 - 가 제시되며, 승인 또는 거절을 선택할 수 있습니다.
거절과 피드백 루프
사용자가 Tool 실행을 거절하면, 거절 사유가 LLM에 functionResponse로 전달됩니다. LLM은 이 피드백을 이해하고 대안을 제시하거나 추가 확인을 요청합니다.
sequenceDiagram participant U as 사용자 participant AI as AI 에이전트 participant DB as DB U->>AI: "유저 A의 골드를 0으로 만들어줘" AI->>U: DB update 승인 요청 (gold: 0) U--xAI: 거절 - "0이 아니라 1000으로 설정해줘" AI->>U: DB update 승인 요청 (gold: 1000) U->>AI: 승인 AI->>DB: update (gold: 1000) DB->>AI: 성공 AI->>U: "골드를 1000으로 설정했습니다"
이 거절-피드백 루프는 자연스러운 대화 흐름 안에서 이루어집니다. 시스템 오류가 아닌 사용자의 의사 표현으로 처리되므로, AI는 에러 메시지 대신 대화적으로 응답합니다.
에이전트 오케스트레이션: Chat Loop 상태 머신
루프 구조와 종료 조건
시스템의 핵심은 runChatLoop 함수입니다. 사용자의 하나의 메시지에 대해 AI가 여러 차례 Tool을 호출하고, 그 결과를 다시 AI에 전달하여 최종 텍스트 응답을 생성할 때까지 반복합니다.
사용자 메시지
-> AI 응답 (Tool 호출)
-> Tool 실행
-> AI 응답 (또 다른 Tool 호출)
-> Tool 실행
-> AI 응답 (텍스트)
-> 완료루프는 세 가지 조건에서 종료됩니다.
- AI가 텍스트만 반환하고 Function Call이 없는 경우 - 정상 종료
- Tool이 승인을 필요로 하는 경우 - 일시 중단, 사용자 승인 대기
- 최대 반복 횟수(20회)를 초과한 경우 - 안전 차단
const MAX_LOOP_ITERATIONS = 20;
const MAX_EMPTY_RETRIES = 2;
let continueLoop = true;
let loopCount = 0;
while (continueLoop) {
continueLoop = false;
loopCount++;
if (loopCount > MAX_LOOP_ITERATIONS) {
session.messages.push({
role: "assistant",
content: "반복 횟수가 최대 한도를 초과했습니다.",
timestamp: new Date(),
});
break;
}
// LLM 호출 -> 응답 파싱 -> Tool 실행 또는 텍스트 반환
// Tool 실행 결과가 있으면 continueLoop = true
}승인 대기 시에는 루프가 return으로 완전히 종료됩니다. 사용자가 승인하면 별도의 processApproval 함수가 호출되어 새로운 루프가 시작됩니다. 이 방식은 서버가 상태를 메모리에 유지할 필요 없이, DB에 저장된 세션 상태만으로 중단/재개가 가능하다는 장점이 있습니다.
안전 경계
LLM은 비결정적(non-deterministic) 시스템이므로, 예측 불가능한 동작에 대한 방어가 필수적입니다.
- 최대 반복 제한: AI가 Tool을 무한히 호출하는 상황을 방지합니다. 20회 제한은 실무적으로 충분한 여유를 두면서도 무한 루프를 차단합니다.
- 빈 응답 방어: LLM이 텍스트도 Function Call도 반환하지 않는 경우(MALFORMED_FUNCTION_CALL 등)를 감지하여, 최대 2회 자동 재시도 후 사용자에게 에러를 알립니다.
- validation_error 재시도: Tool 실행에서 입력값 검증 실패가 발생하면, LLM에 에러를 피드백하여 수정된 인자로 재시도할 기회를 줍니다(기본 최대 2회).
for (let attempt = 0; attempt <= maxRetries; attempt++) {
const result = await tool.execute(context);
if (result.status !== "validation_error") {
return result; // 성공 또는 다른 에러면 즉시 반환
}
// validation_error -> 다음 시도
}
// 최대 재시도 초과 -> validation_error 그대로 반환스트리밍 응답과 실시간 상태 전파
사용자 경험을 위해 AI의 응답 생성 과정을 실시간으로 전파합니다. 세션 상태는 DB 문서에 저장되며, 클라이언트는 실시간 리스너(WebSocket, DB snapshot listener 등)로 상태 변화를 감지합니다.
세션 상태 전이는 다음과 같습니다.
stateDiagram-v2 idle --> thinking: 메시지 수신 (thinking mode) idle --> generating: 메시지 수신 thinking --> generating: 사고 완료 generating --> done: 텍스트 응답 generating --> awaiting_approval: 승인 필요 Tool generating --> executing: 자동 실행 Tool awaiting_approval --> executing: 승인 awaiting_approval --> generating: 거절 executing --> generating: Tool 완료
Thinking Mode가 활성화된 경우, LLM의 사고 과정(thinking)이 먼저 스트리밍되고 이어서 실제 응답(generating)이 스트리밍됩니다.
System Prompt 엔지니어링
동적 프롬프트 구성
System Prompt는 정적 텍스트가 아니라 매 루프 반복마다 동적으로 생성됩니다. 이는 세션 진행 중에 에셋 목록이 변하거나, 첫 응답에만 인사를 포함시키는 등의 상황을 반영하기 위함입니다.
프롬프트는 다음 섹션으로 구성됩니다.
| 섹션 | 내용 | 동적 여부 |
|---|---|---|
| 기본 역할 | AI의 역할, 기능, Tool 사용 가이드 | 정적 |
| 사용자 정보 | 현재 사용자 이름, 직함, 역할 | 첫 응답만 |
| 서비스 컨텍스트 | 대상 서비스 ID, 이름, 설명 | 세션별 |
| 도메인 규칙 | 서비스별 제약사항 (우선순위 정렬) | 세션별 |
| 에셋 목록 | 현재 세션의 파일 목록 (ID, 파일명, 크기) | 매 반복 |
function buildSystemPrompt(
appName: string,
adminName: string,
adminProfile: AdminProfile | null,
isFirstResponse: boolean,
assets: AssetMetadata[]
): string {
return (
BASE_PROMPT +
buildAdminSection(adminName, adminProfile, isFirstResponse) +
buildAppContextSection(appName) +
buildRulesSection(appName) +
buildAssetSection(assets)
);
}이 구조는 “필요한 정보를 필요한 시점에만” 주입하는 원칙을 따릅니다. 사용자 이름과 직함은 첫 응답의 인사에만 필요하고, 에셋 목록은 Tool 실행으로 파일이 추가될 때마다 갱신되어야 합니다.
도메인 규칙 동적 주입
서비스별로 고유한 제약사항이 존재할 수 있습니다. “이 서비스에서는 유저 데이터 삭제가 금지됨”, “통화 수정 시 반드시 현재 값을 먼저 조회할 것” 같은 규칙이 그 예입니다. 이러한 규칙은 DB에 저장되고 우선순위에 따라 정렬되어 System Prompt에 주입됩니다.
규칙을 DB에 저장하는 방식의 장점은 코드 재배포 없이 규칙을 추가/수정할 수 있다는 것입니다. 새로운 제약사항이 생기면 DB에 규칙을 추가하기만 하면 AI가 즉시 반영합니다. 이는 RAG와 같은 맥락으로, 시스템의 지식과 행동 지침을 코드에서 분리하여 운영 유연성을 높입니다.
보안: RBAC 기반 Tool 접근 제어
역할 기반 권한 모델
AI 에이전트가 강력한 Tool을 가진다면, 누가 어떤 Tool을 사용할 수 있는지 제어하는 것이 필수적입니다. 여기서는 RBAC를 Tool 수준까지 확장합니다.
Tool별 권한 검사
각 Tool은 선택적으로 checkPermission 함수를 정의할 수 있습니다. 이 함수는 Tool 실행 전에 호출되어, 현재 사용자의 역할과 호출 인자를 기반으로 실행 허용 여부를 판단합니다.
// Tool 실행 전 권한 검사
const permResult = await checkToolPermission(
adminInfo.permissions || [],
toolName,
args,
appName
);
if (!permResult.allowed) {
return {
toolCallId,
toolName,
status: "permission_denied",
reason: permResult.reason || `Permission denied`,
};
}HITL 승인과 RBAC 권한 검사는 별개의 계층입니다. RBAC가 먼저 적용되어 “이 사용자가 이 작업을 할 자격이 있는가”를 판단하고, 통과한 경우에만 HITL이 “정말 이 작업을 실행할 것인가”를 묻습니다. 이중 안전장치를 통해, AI 에이전트의 강력한 기능이 적절한 권한과 의도를 가진 사용자에게만 제공됩니다.
대용량 결과 처리: Auto-Trim과 에셋 시스템
40KB 임계값 기반 자동 축약
DB 조회 결과가 대량일 경우, 전체 데이터를 LLM 컨텍스트에 넣으면 토큰이 급증하고 처리 속도가 저하된다는 것을 실험 과정에서 발견했습니다. 이를 방지하기 위해 40KB 임계값 기반의 자동 트리밍 메커니즘을 도입했습니다.
const AUTO_TRIM_THRESHOLD = 40 * 1024; // 40KB
const AUTO_TRIM_HEAD = 15 * 1024; // 15KB
const AUTO_TRIM_TAIL = 15 * 1024; // 15KB트리밍 동작 방식은 다음과 같습니다.
- Tool 실행 결과의 직렬화된 크기가 40KB를 초과하는지 확인합니다
- 초과하면 원본 전체를 파일 스토리지에 에셋으로 저장합니다
- LLM에는 앞 15KB + 뒤 15KB의 미리보기와 데이터 구조 분석 요약을 전달합니다
- AI가 전체 데이터를 분석해야 할 경우, 에셋 관리 Tool의 검색/범위 조회 기능을 사용합니다
RAG 검색 결과(search-docs)는 트리밍 블랙리스트에 등록되어 있어, 스키마 문서는 항상 전체가 LLM에 전달됩니다. 도메인 지식은 축약하면 의미가 손상될 수 있기 때문입니다.
에셋 기반 대용량 데이터 워크플로우
이 시스템의 설계 초기에 CLI 기반 AI 에이전트에서 영감을 받았다고 언급한 바 있습니다. 그런 에이전트들은 로컬 파일시스템에 파일을 두고 읽고, 편집하고, 가공하는 방식으로 동작합니다. 에셋 시스템은 이 패턴을 서버 환경에서 최소 기능으로 재현한 것입니다 - 세션 단위의 가상 파일 공간에서, AI가 데이터를 저장하고 탐색하고 가공할 수 있게 합니다.
단순히 트리밍된 데이터를 저장하는 것 이상의 역할을 하며, 사용자가 직접 파일을 업로드하거나 Tool 결과를 명시적으로 저장하여 세션 내에서 재사용할 수도 있습니다.
CLI AI 에이전트의 대용량 파일 처리 방식
예를 들어 Claude Code에 10MB짜리 JSON 파일을 분석해달라고 요청하면, 파일 전체를 컨텍스트에 올리지 않습니다. 먼저 파일의 일부만 읽어 구조를 파악하고, grep으로 관심 패턴을 검색하여 위치를 특정한 뒤, 해당 범위만 정밀하게 읽습니다. 본 시스템의 에셋 워크플로우는 이 동작을 API 기반 Tool로 재현한 것입니다.
대용량 데이터 분석의 전형적인 워크플로우는 다음과 같습니다.
file_stats- 파일 구조 파악 (타입, 키, 행 수 등)search_text- 패턴 기반 검색으로 관심 영역 특정read_range- 특정 행 범위만 읽어 상세 분석
이 점진적 탐색 패턴은 LLM 컨텍스트를 효율적으로 사용하면서도, 수 MB 규모의 데이터를 분석할 수 있게 합니다.
마치며 - 폐쇄망 호환성과 확장 가능성
이 글에서 다룬 아키텍처의 모든 구성 요소 - RAG 파이프라인, Tool 시스템, HITL 승인, RBAC 보안 - 는 인터넷 연결 여부에 관계없이 동작할 수 있도록 설계되었습니다.
- LLM: 클라우드 API 대신 온프레미스 sLLM(Llama, Mistral 등)을 배포하면 폐쇄망에서도 동일한 Function Calling 기반 에이전트를 운용할 수 있습니다.
- 임베딩: 온디바이스 임베딩 모델(ONNX Runtime, TensorRT 등)로 대체 가능합니다.
- 벡터 DB: 폐쇄망 내 PostgreSQL + pgvector나 로컬 Qdrant 인스턴스로 구동됩니다.
- Tool 실행: 이미 백엔드 서버에서 로컬로 수행되므로 외부 의존성이 없습니다.
특히 보안이 중요한 환경에서는 내부망 운용이 필수적입니다. 국방부의 GeDAI(Generative Defense AI)가 sLLM 기반으로 보안 내부망에서 운용되는 것처럼, 본 시스템의 RAG + Tool + HITL 아키텍처는 폐쇄 환경에서의 도메인 특화 AI 에이전트 구축에 실질적인 참조 모델이 될 수 있습니다.
실제 효과 - 도입부의 문제가 해결되었는가
도입부에서 기존 관리자 패널의 유연성 부재를 언급했습니다. 이 시스템이 실전에서 그 문제를 해결한 사례가 있습니다.
서비스 업데이트 과정에서 일부 데이터의 ID 체계가 변경되면서, 기존 사용자들에게 데이터 마이그레이션이 필요한 상황이 발생했습니다. 문제는 이것이 주말에 터졌고, 일괄 배치 스크립트로 처리할 수 없는 케이스였다는 것입니다 - 사용자의 업데이트 여부에 따라 마이그레이션 방식이 달라졌기 때문에, CS 문의가 오는 건별로 대응해야 했습니다.
기존 관리자 패널이었다면 이 기능이 없었을 것이고, 개발팀에 건별로 DB 쿼리를 요청하는 수밖에 없었습니다. 하지만 이번에는 달랐습니다. Slack에 프롬프트 템플릿을 공유하고 “이렇게 보내시면 됩니다”라고 안내하는 것만으로 충분했습니다.
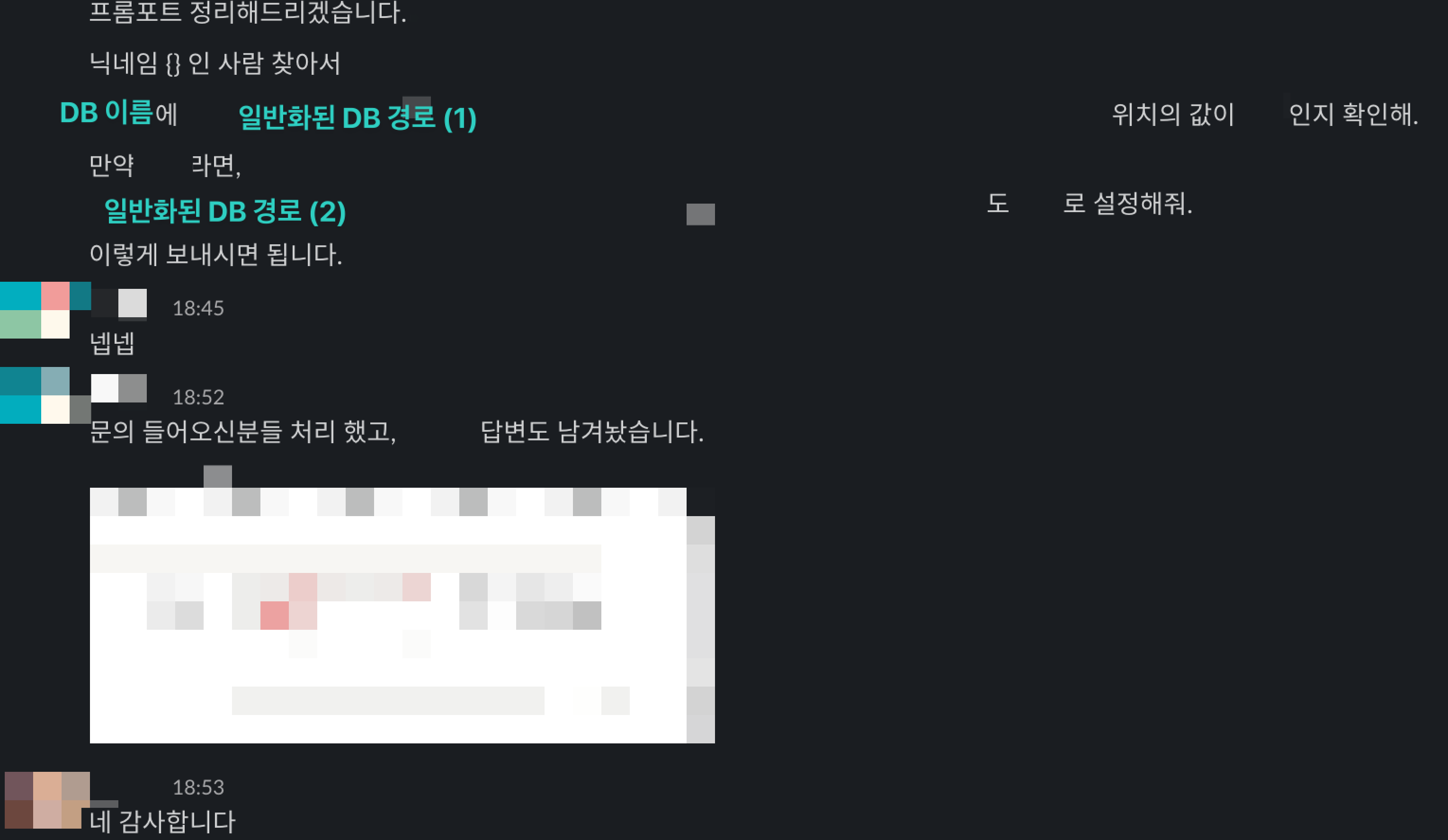
CS팀이 AI 에이전트에 자연어로 요청하여 자체적으로 문제를 해결했고, 개발팀은 주말에 호출되지 않았습니다.
실제 처리 플로우는 단순하지 않았습니다. 닉네임으로 사용자를 검색하여 UID를 확인하고, 해당 사용자의 마이그레이션 대상 값을 조회하여 조건을 판별한 뒤, 조건에 맞는 마이그레이션을 실행하는 - 여러 단계의 Tool 호출이 필요한 작업이었습니다. AI 에이전트는 이 전체 플로우를 문제 없이 수행했습니다.
새로운 기능을 구현한 것이 아닙니다 - AI가 이미 가진 DB 조작 Tool과 스키마 문서만으로, 예상하지 못했던 상황에 유연하게 대응한 것입니다.
사내 도구라는 출발점에서 설계된 시스템이지만, “내부 도메인 지식을 기반으로 안전하게 데이터를 조작하는 AI 에이전트”라는 핵심 문제는 분야를 가리지 않습니다. 스키마 문서를 교범으로, DB Tool을 데이터 조회로, 승인 시스템을 결재 체계로 대체하면, 동일한 아키텍처가 전혀 다른 도메인에서도 작동합니다.